SkillsBench 1.1 is the current release of the benchmark for evaluating how AI agents use Agent Skills: structured packages of instructions, scripts, and reference material mounted at inference time.
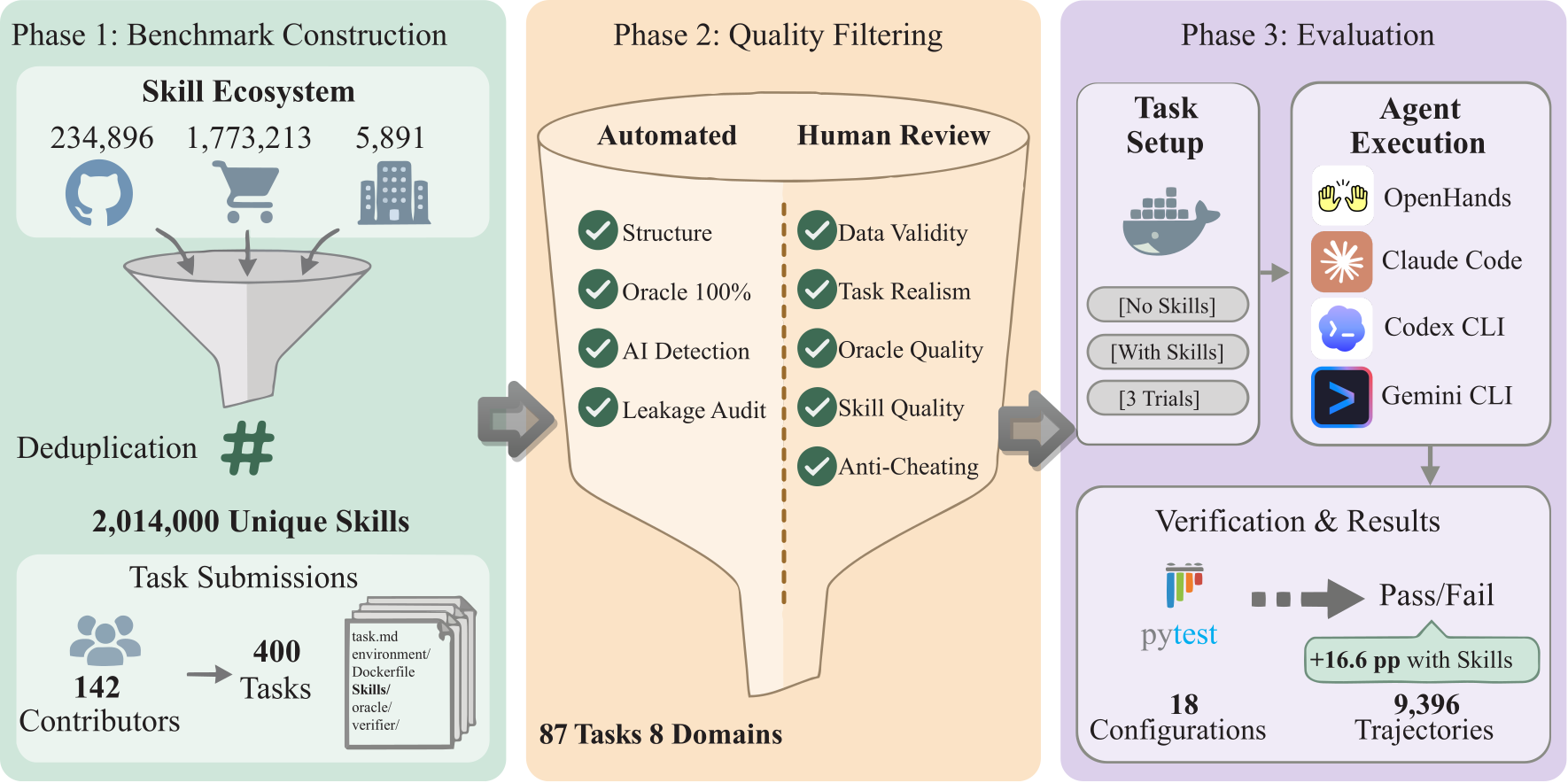
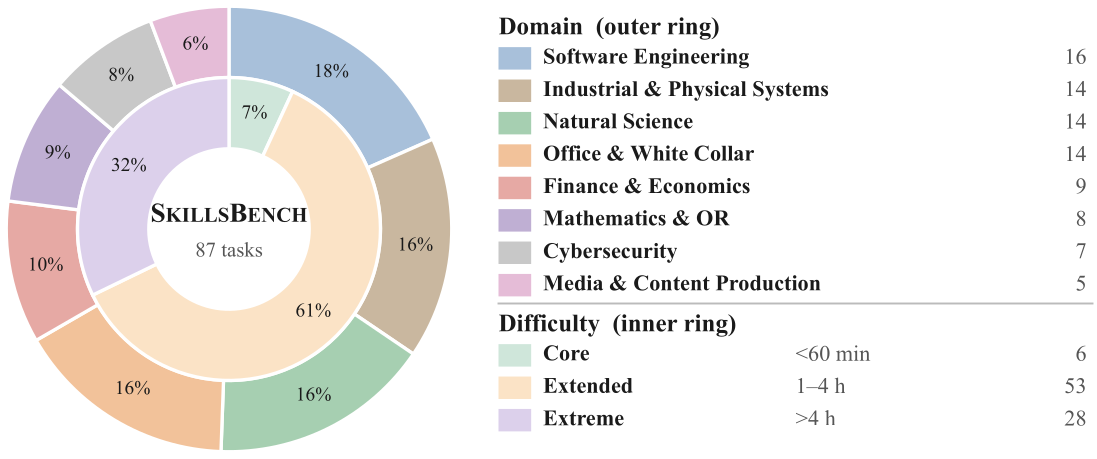
The v1.1 paper, SkillsBench: Benchmarking How Well Agent Skills Work Across Diverse Tasks, is available on arXiv. The current arXiv version reports an inventory of 87 tasks across 8 domains, paired evaluation with and without curated Skills, and aggregate results over 18 model-harness configurations. We are honored to have Prof. Dawn Song joins us as advising author.
The benchmark tasks set release is pinned as GitHub release v1.1, mirrored on Hugging Face, and accompanied by public trajectories in the SkillsBench leaderboard dataset.
Release Contents
- 87 native BenchFlow tasks. The v1.1 roster is packaged as native
task.mdtasks withenvironment/,oracle/, andverifier/directories. - 8 domains. The task taxonomy covers Software Engineering, Industrial & Physical Systems, Natural Science, Office & White Collar, Finance & Economics, Mathematics & OR, Cybersecurity, and Media & Content Production.
- Four harnesses in the paper aggregate. The paper reports Claude Code, Codex, Gemini CLI, and OpenHands.
- 18 paper configurations and 25 public leaderboard configurations. The paper aggregate covers 18 model-harness configurations. The live leaderboard currently tracks 24 paired configurations plus one with-Skills-only result on the same 87-task roster.
- Skill-invocation tracking. With-Skills runs record whether an agent reads or invokes the task-specific Skills it is given.
- BenchFlow compatibility. The release experiment runs on BenchFlow as the evaluation harness.
- Additional distribution surfaces. SkillsBench 1.1 is also available through Prime Intellect, AgentBeats, and Harbor.
Credential-dependent or integration-incompatible packages remain under tasks-extra/ and are excluded from the default benchmark roster.
Method
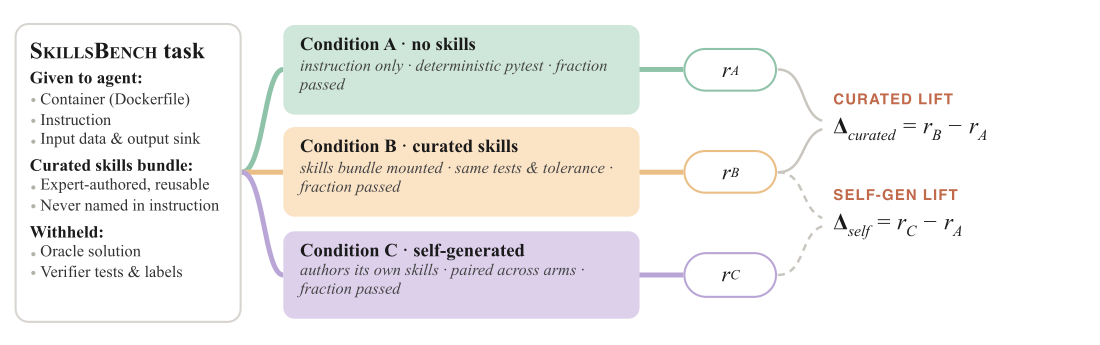
SkillsBench uses paired evaluation. The same task is run in the same container under matched no-Skills and curated-Skills conditions, so "Skill Lift" is measured at the task and configuration level.
Task Suite
Results
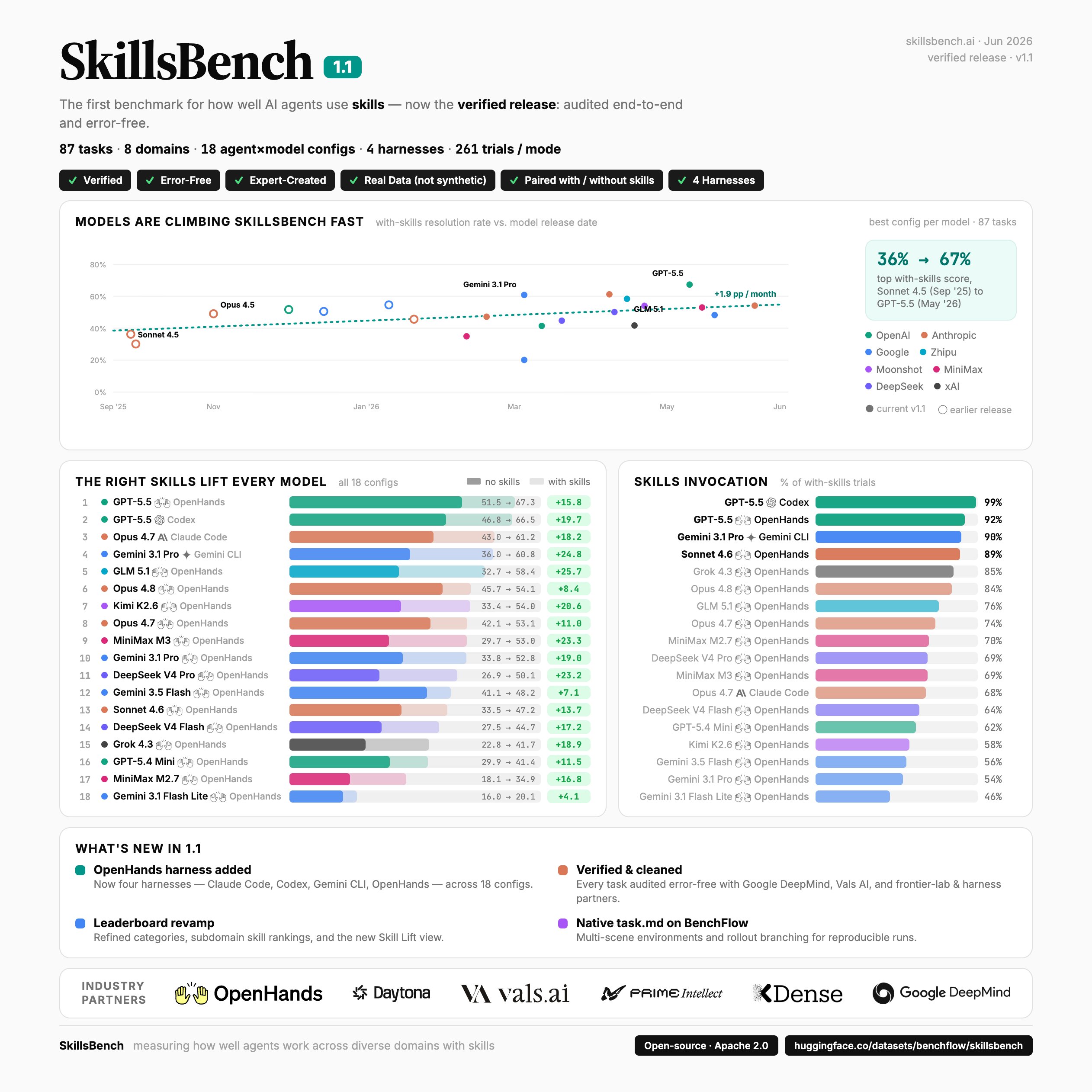
With-Skills Resolution Rate Over Time
The release-date chart reports a rise from 36.2% with-Skills resolution rate for Claude Code + Sonnet 4.5 to 67.3% for OpenHands + GPT-5.5. Using the plotted release-month annotations, the fitted increase is about +1.9 points per month.
On Claude Code, the model-generation sequence is:
| Claude Code model | No Skills | With Skills |
|---|---|---|
| Haiku 4.5 | 8.8 | 30.1 |
| Sonnet 4.5 | 16.7 | 36.2 |
| Opus 4.5 | 23.8 | 49.0 |
| Opus 4.6 | 33.7 | 50.2 |
| Opus 4.7 | 43.0 | 61.2 |
The highest with-Skills result in the current public leaderboard is OpenHands + GPT-5.5 at 67.3%.
The newest candidate row is Claude Code + Tencent Hunyuan HY3 at 55.9% with Skills across 87 tasks × 3 trials. It is shown as a one-sided result because the submission does not include a matched no-Skills ablation.
Curated Skills Across Configurations
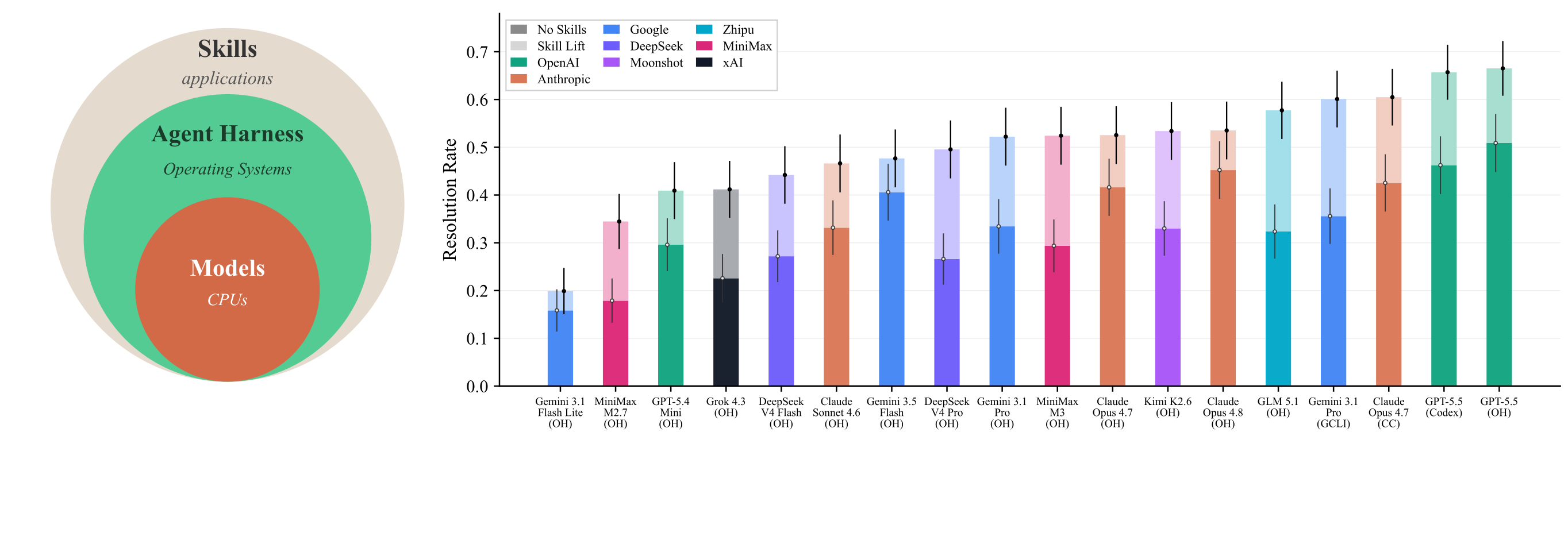
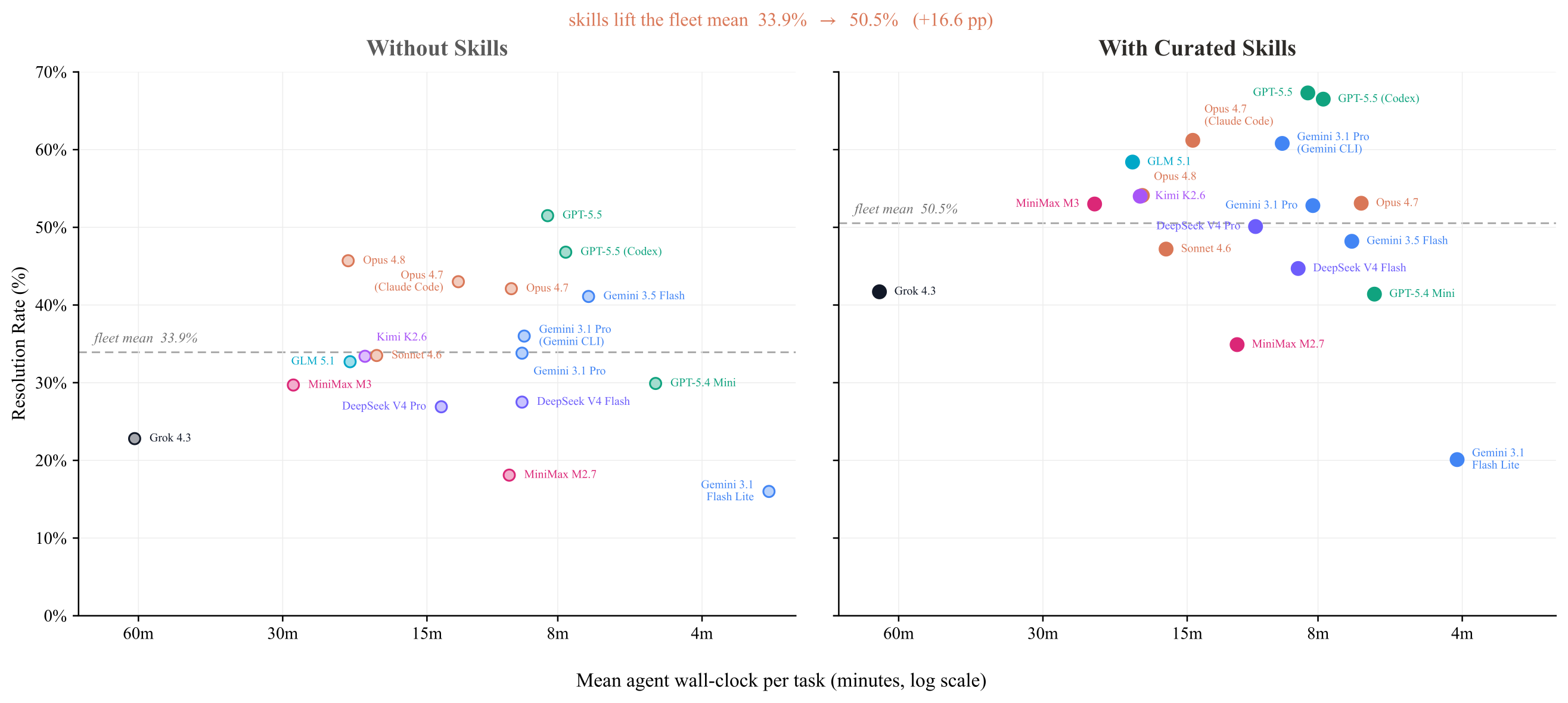
In the 18-configuration paper aggregate, all configurations have higher resolution rates with curated Skills. The mean resolution rate rises from 33.9% to 50.5% (+16.6 points; 25.5% normalized gain), with configuration-level gains from +4.1 to +25.7 points.
| Harness + Model | No Skills | With Skills | "Skill Lift" |
|---|---|---|---|
| OpenHands · GPT-5.5 | 51.5 | 67.3 | +15.8 |
| Codex · GPT-5.5 | 46.8 | 66.5 | +19.7 |
| Claude Code · Opus 4.7 | 43.0 | 61.2 | +18.2 |
| Gemini CLI · Gemini 3.1 Pro | 36.0 | 60.8 | +24.8 |
| OpenHands · GLM 5.1 | 32.7 | 58.4 | +25.7 |
| OpenHands · Opus 4.8 | 45.7 | 54.1 | +8.4 |
| OpenHands · MiniMax M3 | 29.7 | 53.0 | +23.3 |
| OpenHands · DeepSeek V4 Pro | 26.9 | 50.1 | +23.2 |
The largest lifts in the public leaderboard table are OpenHands + GLM 5.1 (+25.7), Gemini CLI + Gemini 3.1 Pro (+24.8), OpenHands + MiniMax M3 (+23.3), and OpenHands + DeepSeek V4 Pro (+23.2).
The live leaderboard is recomputed from the public Hugging Face trajectory dataset. It currently covers 24 paired configurations plus one with-Skills-only result. The paired-config with-Skills mean remains 49.2%; the one-sided HY3 row is excluded from lift and fleet-mean calculations.
Cross-Model Comparisons
Selected comparisons in the public leaderboard:
| Comparison | No-Skills reference | With-Skills result |
|---|---|---|
| GLM 5.1 with Skills vs. Opus 4.8 without Skills | OpenHands · Opus 4.8: 45.7 | OpenHands · GLM 5.1: 58.4 |
| MiniMax M2.7 with Skills vs. GLM 5.1 without Skills | OpenHands · GLM 5.1: 32.7 | OpenHands · MiniMax M2.7: 34.9 |
| MiniMax M2.7 with Skills vs. MiniMax M3 without Skills | OpenHands · MiniMax M3: 29.7 | OpenHands · MiniMax M2.7: 34.9 |
"Skill Lift" By Domain
"Skill Lift" is positive in all 8 domains in the paper aggregate.
| Domain | N | No Skills | With Skills | "Skill Lift" |
|---|---|---|---|---|
| Natural Science | 14 | 42.0 | 70.8 | +28.8 |
| Media & Content Production | 5 | 23.3 | 47.4 | +24.1 |
| Cybersecurity | 7 | 29.5 | 48.4 | +18.9 |
| Industrial & Physical Systems | 14 | 23.9 | 39.6 | +15.7 |
| Finance & Economics | 9 | 19.1 | 33.3 | +14.2 |
| Office & White Collar | 14 | 40.5 | 53.0 | +12.6 |
| Software Engineering | 16 | 37.6 | 49.2 | +11.6 |
| Mathematics & OR | 8 | 45.7 | 55.4 | +9.7 |
Across tasks, 13 of 87 tasks have negative "Skill Lift" in the paper aggregate.
Skill Invocation Rate
Skill Invocation Rate is the share of with-Skills trials in which the agent reads or invokes the task-specific Skills it is given.
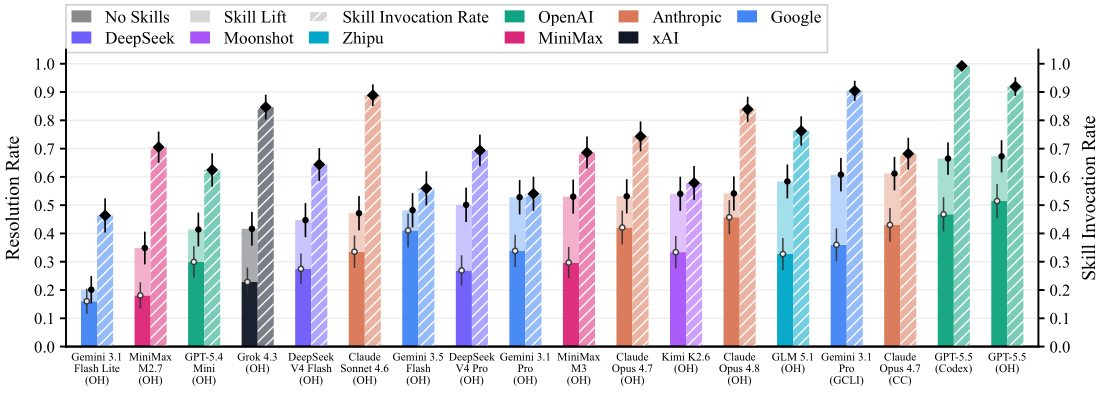
Invocation rates range from 46% to 99%. Codex + GPT-5.5 is at 99%, OpenHands + GPT-5.5 at 92%, Gemini CLI + Gemini 3.1 Pro at 90%, and OpenHands + Sonnet 4.6 at 89%. Some failed runs still include a recorded Skill invocation.
Self-Generated Vs. Curated Skills
In the self-generated condition, the agent authors its own Skills before solving. The paper reports this condition on three dedicated-harness configurations.
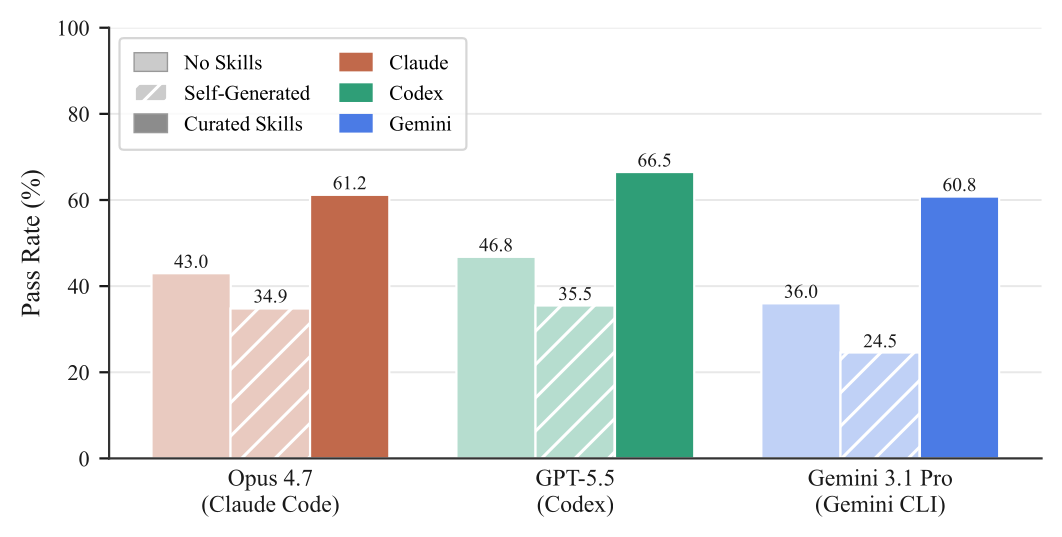
Self-generated Skills change resolution rate by -8.1 points for Claude Code + Opus 4.7, -11.3 points for Codex + GPT-5.5, and -11.5 points for Gemini CLI + Gemini 3.1 Pro. Curated Skills add +18.2 to +24.8 points on the same configurations.
Skill Quantity And Length
"Skill Lift" varies by the number and length of Skills attached to a task.
| Skill quantity | Lift |
|---|---|
| 1 Skill | +18.0 |
| 2-3 Skills | +19.0 |
| 4+ Skills | +10.1 |
| Skill length | Lift |
|---|---|
| Compact | +19.0 |
| Standard | +21.5 |
| Detailed | +14.5 |
| Comprehensive | +0.7 |
Resolution Rate And Agent Time
The paper also reports mean agent wall-clock time per task.
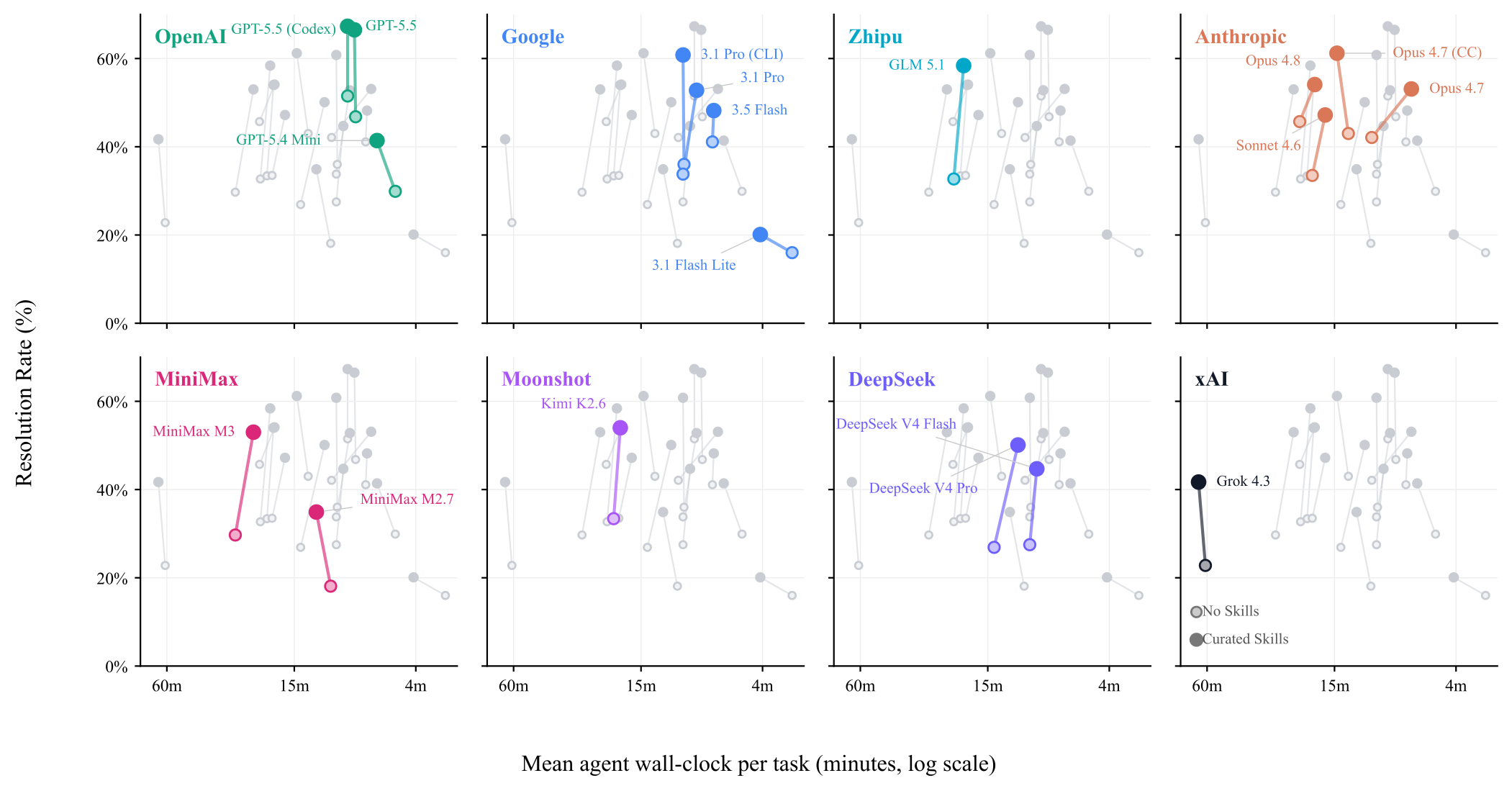
Across the paired fleet, curated Skills add +16.6 points to the mean resolution rate. Mean agent wall-clock per task changes from 14.5 minutes without Skills to 13.8 minutes with Skills in the public leaderboard snapshot.
Citation Count
An internal June 2026 count across Google Scholar, Semantic Scholar, and arXiv found about 130 citations of SkillsBench over roughly four months. Citation counts are approximate and change over time.
Acknowledgements
The v1.1 paper and release include contributions from the SkillsBench author and contributor group listed on arXiv. The launch materials acknowledge support from Google DeepMind, Kaggle, OpenHands, Modal, Daytona, Prime Intellect, KDense, Vals AI, and other infrastructure and evaluation partners.
Resources
- Website: skillsbench.ai
- Leaderboard: skillsbench.ai/leaderboard
- Paper: arXiv abstract and PDF
- GitHub: benchflow-ai/skillsbench and v1.1 release tag
- Hugging Face: dataset and leaderboard trajectory dataset
- BenchFlow SDK: benchflow-ai/benchflow for SkillsBench 1.1
SkillsBench and its evaluation infrastructure are open source under the Apache 2.0 license. Contributions of tasks, Skill sets, and harnesses are accepted through the project repository.